[딥러닝 모델 경량화] MobileNet
지난번 Xception 모델에 이어서 오늘은 MobileNet에 대하여 알아보도록 하겠습니다:^D
2020/08/02 - [Deep Learning/papers] - [딥러닝 모델 경량화] Xception
[딥러닝 모델 경량화] Xception
[딥러닝 모델 경량화] Xception 안녕하세요 오늘은 Inception으로부터 발전한 Xception에 대해서 알아보도록 하겠습니다! Inception에 대한 자세한 설명은 지난 글에서 확인하실 수 있습니다. 2020/08/02 - [Dee
sotudy.tistory.com
PR12라는 논문 읽기 유튜브가 있는데 여기서 MobileNet에 대한 발표를 듣고 논문을 읽으니 좀 더 수월하였습니다!
다양한 최신 논문들을 다루기 때문에 공부하실때 참고하시면 좋겠습니다.
MobileNet 발표영상은 여기에 링크 걸어두겠습니다!
MobileNet은 구글에서 2017년에 발표하였습니다.
Xception이랑 아이디어는 똑같습니다.
그럼에도 이 논문이 갖는 가치는 다음과 같습니다.
1. 다양한 분야에 이 논문을 적용했습니다.
2. 다양한 분야에서 좋은 성능을 보여줬습니다.
3. 성능보다는 efficiency 관점에서 논문이 쓰여졌습니다.

MobileNet 구조
이 모델의 key idea는 Depthwise Separable Convolution입니다.
Xception이랑 다른 점은 Xception은 shortcut이 있고, 1x1 → 3x3 conv를 사용하지만 MobileNet은 3x3 → 1x1 이 순서로 conv block을 구성하고 non-linearity가 추가되었다는 것입니다.
아래 그림 2의 오른쪽 block을 보시면 3 x 3 Depthwise Convolution과 1 x 1 Convolution 사이에 Batchnormalization과 ReLU가 추가되어 있는 것을 볼 수 있습니다.

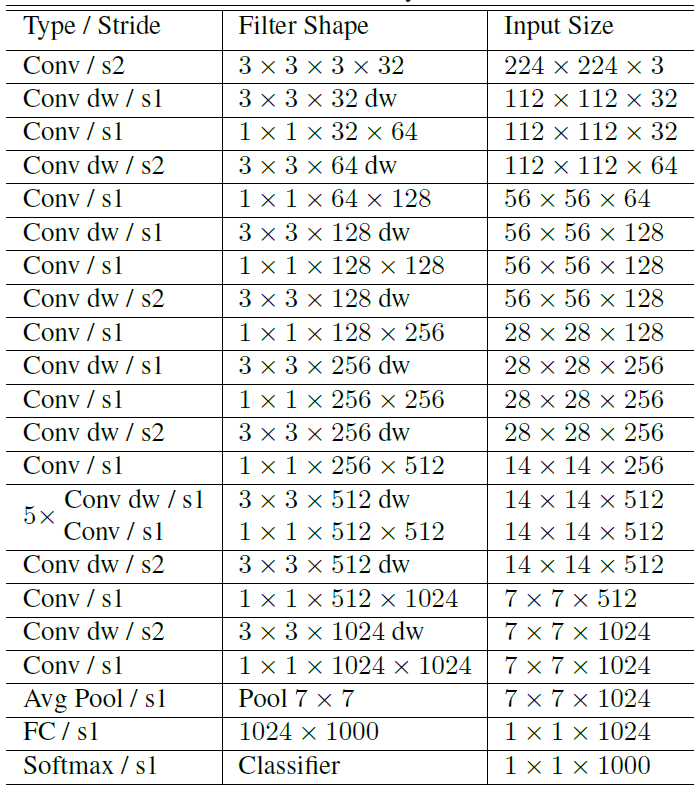
전체 구조는 아래 표를 보시면 쉽게 이해할 수 있습니다.
첫 레이어에는 Conv라는 것이 들어가는데 이것이 Standard Convolution입니다. 처음에는 Depthwise Separable Convolution이 아닌 일반적으로 사용하는 Convolution을 사용합니다.
그리고 Conv dw가 Depthwise Convolution입니다.
이렇게 Depthwise Separable Convolution을 쌓은 모델이 MobileNet입니다.
이렇게 논문이 끝나면 너무 Xception과 비슷하죠?
여기서 끝나지 않고 Width Multiplier과 Resolution Multiplier라는 개념을 소개합니다.
Width Multiplier
input channel M과 output channel(filter개수와 동일) N에 $\alpha$를 곱해서 채널을 줄이는 역할을 합니다.
전 포스팅 중에 다양한 종류의 convolution에서 파라미터수와 연산량을 계산한 적이 있는데 거기를 보면 좀 더 이해하기 쉬우실 것입니다.
Width Multiplier $\alpha$를 곱한 depthwise separable convolution의 연산량은 다음과 같습니다.
여기서 $\alpha$는 0과 1 사이의 수고 보통 1, 0.75, 0.5, 0.25를 사용합니다.
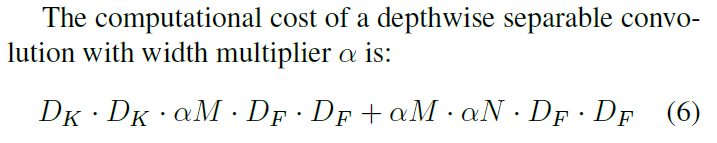
- $D_K*D_K$ : kernel size (filter size)
- $M$ : input channel
- $D_F*D_F$ : input
- $N$ : output channel (filter 개수)
기존의 연산량과 $\alpha^2$ 만큼 차이가 난다고 합니다.
Resolution Multiplier
Resolution Multiplier은 Input의 가로 세로 크기를 줄여서 연산량을 줄이는 역할을 합니다.
$\rho$를 input의 width와 height에 곱합니다.
다음 수식은 $\alpha$를 곱해서 채널을 줄이고 $\rho$를 곱해서 해상도를 줄인 Depthwise separable convolution의 연산량입니다.
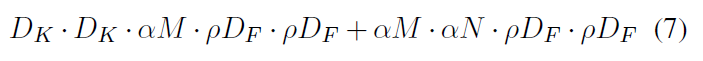
결과 비교

아까 앞에서 본 MobileNets의 body structure에 Depthwise Separable convolution 대신에 일반적인 convolution을 사용한 것이 Conv MobileNet입니다. Conv MobileNet에 비해 MobileNet의 Accuracy는 1% 정도 떨어졌지만 Mult-Adds와 Parameters는 엄청 줄었다는 것을 알 수 있습니다.
여기서 Mult-Adds는 한 이미지를 인식하는 데 필요한 곱셈-합 연산 횟수입니다.

위의 표를 통해 Width Multiplier과 Resolution의 차이에 따른 Accuracy와 연산량의 차이를 알 수 있습니다.
뒤에서는 다양한 분야에 MobileNet을 적용한 사례가 나옵니다.
Stanford Dog datasets, Face Attributes, Object Detection 등의 사례에서 잘 작동한다는 것을 확인할 수 있습니다.
이것으로 MobileNet에 대한 설명을 마치겠습니다.
정리하자면 MobileNet은 Xception과 정말 비슷하지만 Depthwise Separable convolution 사이에 non-linearity를 추가하였고 Width Multiplier, Resolution Multiplier을 사용하여 다양한 하이퍼 파라미터를 사용해서 비교를 해줬습니다. 또한 다양한 사례에 적용을 해봤다는 점이 이 논문의 특징입니다.
참고
[1] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
[2] PR-044 MobileNet
'Deep Learning' 카테고리의 다른 글
| [논문 리뷰] Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (0) | 2020.11.13 |
|---|---|
| [딥러닝 모델 경량화] ShuffleNet (0) | 2020.08.08 |
| [딥러닝 모델 경량화] Xception (3) | 2020.08.02 |
| [딥러닝 모델 경량화] Inception (0) | 2020.08.02 |
| [딥러닝 모델 경량화] 다양한 종류의 Convolution (4) | 2020.08.01 |
댓글