[딥러닝 모델 경량화] Xception
안녕하세요 오늘은 Inception으로부터 발전한 Xception에 대해서 알아보도록 하겠습니다!
Inception에 대한 자세한 설명은 지난 글에서 확인하실 수 있습니다.
2020/08/02 - [Deep Learning/papers] - [딥러닝 모델 경량화] Inception
[딥러닝 모델 경량화] Inception
[딥러닝 모델 경량화] Inception 안녕하세요! 저번 포스팅에서 딥러닝 모델 경량화 동향을 살펴보았을 때 합성곱 필터의 변경해서 만든 모델 중 하나인 MobileNet을 봤었죠? 이에 대해서 더 자세히 �
sotudy.tistory.com
앞에서 말했다시피 Xception은 Inception을 기초로 한 모델입니다.
Xception이 Inception으로부터 어떻게 발전하게 되었는지 살펴보겠습니다.
1. Inception module
Inception module은 다음 그림과 같습니다. 이는 Inception v3인데요. 우리가 이전 글에서 본 것과 조금 다르죠? 우리가 봤던 것은 Inception v1 이기 때문입니다. 여기서 5x5→3x3+3x3으로 바뀐 것을 보실 수 있는데, 5x5를 사용하는 것보다 3x3을 두 번 사용하는 것이 더 효과적이기 때문입니다.

Convolution layer은 filter를 가지고 3D space(Height, Width, Channel)를 모두 학습하려고 합니다. 하나의 kernel(filter)로 cross-channel correlation과 spatial correlation을 동시에 mapping 해야 하기 때문입니다.
인셉션 모듈의 아이디어는 이 프로세스를 cross-channel correlation과 spatial correlation을 독립적으로 살펴볼 수 있게 함으로써 이 프로세스를 좀더 쉽고 효율적으로 만든다는 것입니다. 즉, 일반적인 인셉션 모델은 먼저 1x1 convolution을 통해 cross-channel correlation을 살펴보고, 입력 데이터를 원래의 공간보다 작은 3, 4개의 별도 공간에 mapping 한 다음, 이 작은 3D 공간의 모든 상관관계를 3x3, 5x5 convolution을 통해 mapping 합니다.
Single convolution kernel(filter) 하나가 하려는 것을 Spatial correlation(3x3, 5x5)을 분석해주면서 cross-channel correlation(1x1)으로 두 가지 역할을 잘 분산해주기 때문에 Xception 저자는 Inception이 잘 된 것이라고 생각합니다.
이제 우리는 "cross-channel correlation과 spatial correlation의 mapping은 완전히 분리될 수 있다. "고 가설을 세웁니다.
이는 Inception Architecture의 기초가 되는 가설의 더 강력한 버전이기 때문에 "Extreme Inception"을 의미하는 Xception이라고 부릅니다.
즉, Inception을 좀더 강하고 확실하게 해 보자는 것이 바로 Xception입니다.
2. A simplified Inception module
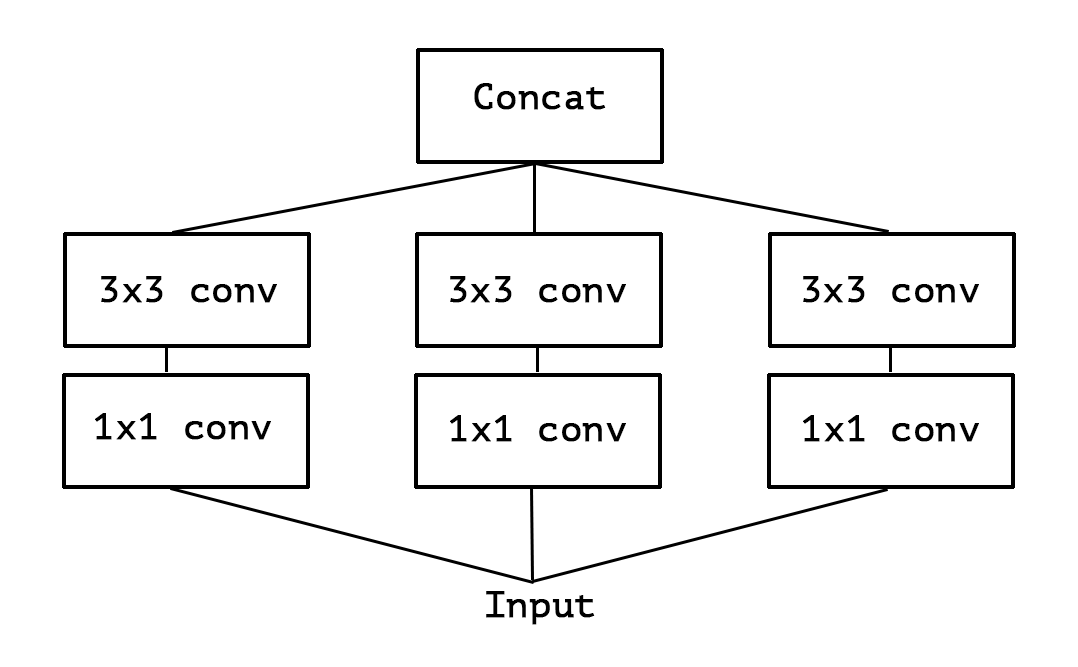
먼저 하나의 크기의 Convolution만 사용하고 averaging pooling을 포함하지 않는 단순화된 Inception module을 만들어준 다음에 아래의 과정으로 갑니다.
3. An "extreme" version of Inception module
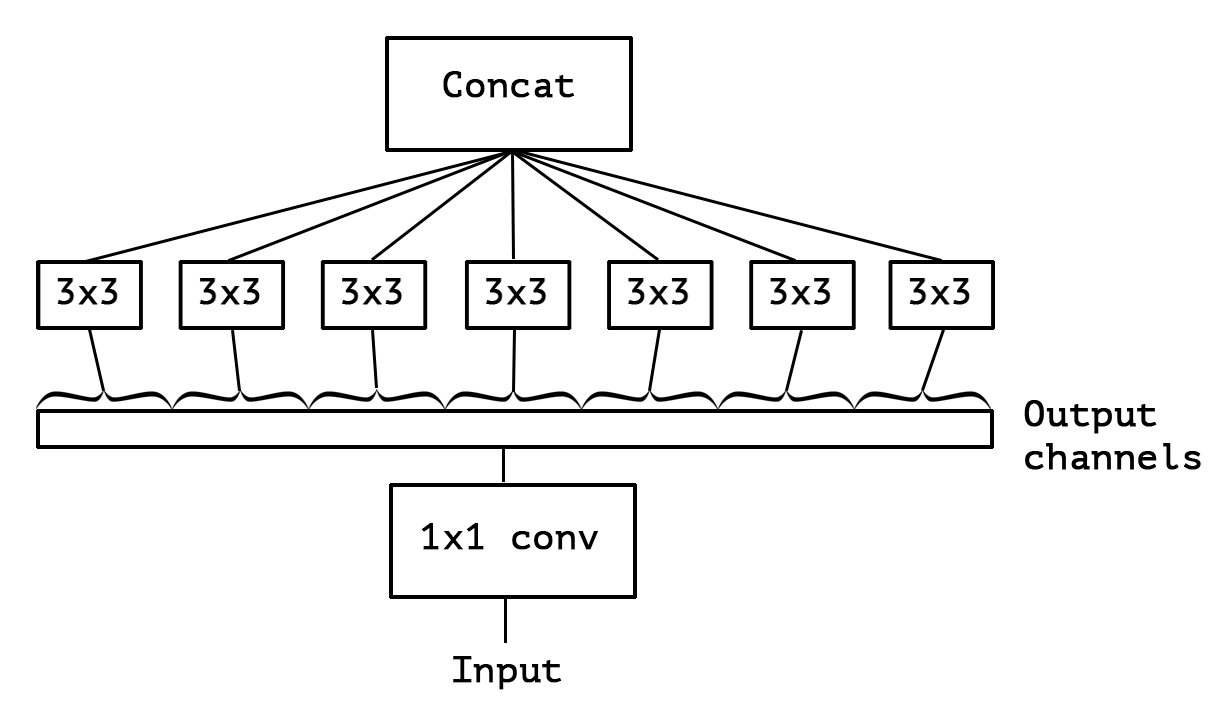
이 Inception module은 대규모 1x1 convolution으로 재구성하고 output channel이 겹치지 않는 부분에 대한 spatial convolution이 오는 형태로 재구성될 수 있습니다. 즉, input에 대해 1x1 convolution을 거친 후에, 모든 channel을 분리시켜서 output channel당 3x3 convolution을 해주는 것입니다. 이렇게 되면 두 방향(channel wise, spatial)에 대한 mapping을 완전히 분리할 수 있습니다.
※ Xception vs Depthwise separable convolution
이는 Depthwise separable convolution이랑 비슷하지만 차이가 있습니다.
1. The order of the operations
Xception: 1x1 → 3x3
Depthwise: 3x3 → 1x1
Xception은 1x1 convolution이 먼저오고 3x3 convolution이 뒤따라 오지만 Depthwise separable convolution은 반대입니다.
2. The presence or absence of a non-linearity after the operation
Xception: 1x1 → ReLU → 3x3
Depthwise: 1x1이랑 spatial convolution 사이에 ReLU 같은 활성화 함수가 들어가지 않습니다.
전체 Xception 구조
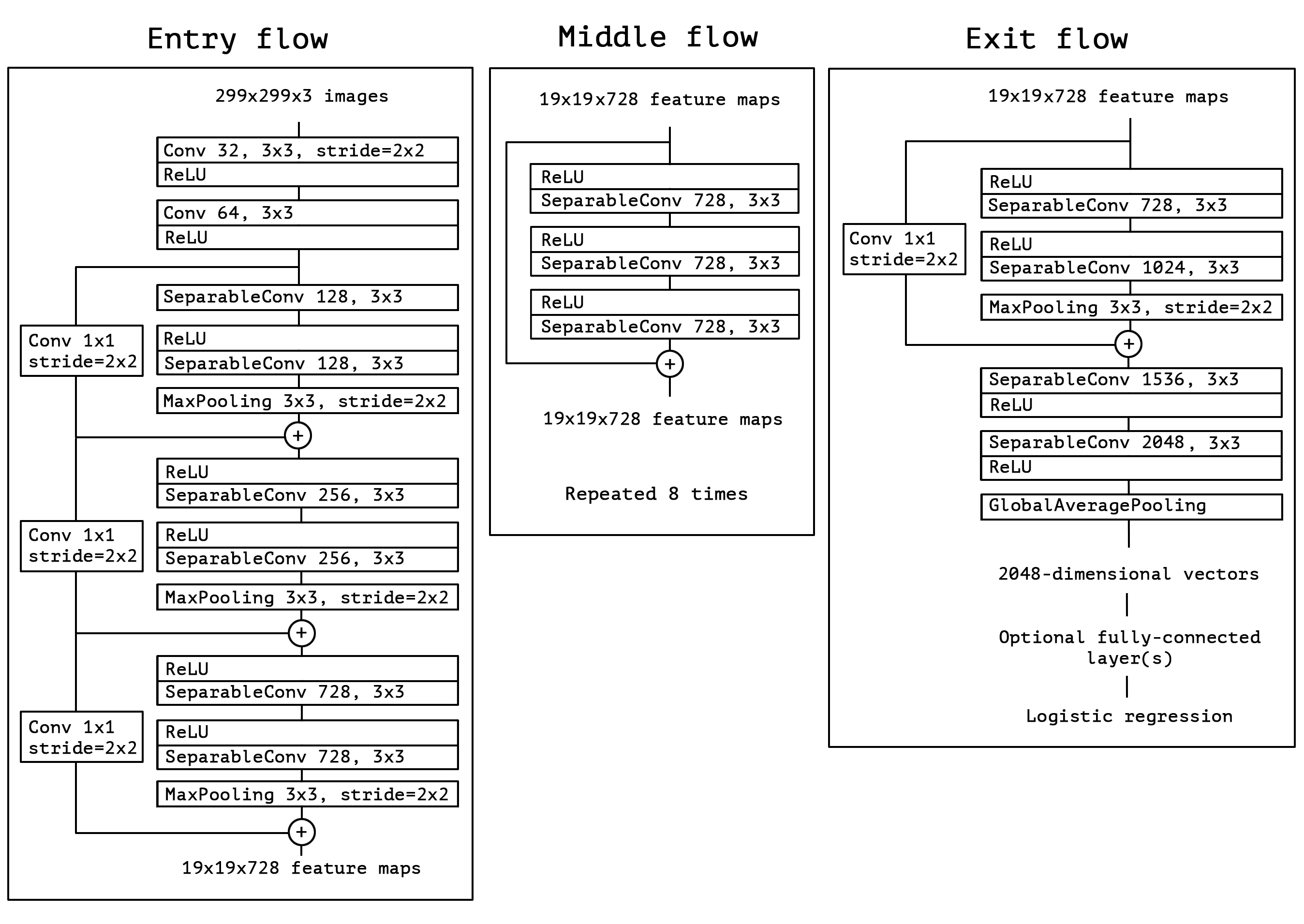
Depthwise Separable Convolution을 Residual과 함께 반복적으로 Stacking 한 구조입니다.
이렇게 Xception에 대해서 알아봤습니다. 저도 이해가 안가는 부분이 조금 있습니다.ㅜㅇㅜ
이에 대해서는 좀 더 알아보고 보충하도록 하겠습니다.
참고
[1] François Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
[2] PR-034: Inception and Xception
'Deep Learning' 카테고리의 다른 글
| [딥러닝 모델 경량화] ShuffleNet (0) | 2020.08.08 |
|---|---|
| [딥러닝 모델 경량화] MobileNet (0) | 2020.08.04 |
| [딥러닝 모델 경량화] Inception (0) | 2020.08.02 |
| [딥러닝 모델 경량화] 다양한 종류의 Convolution (3) | 2020.08.01 |
| [딥러닝 모델 경량화] 딥러닝 경량화 기술 동향 (1) | 2020.08.01 |
댓글