2022.03.06 - [Deep Learning/RL] - [모두RL-②] Dummy Q-Learning (table)에 이어서 김성훈 교수님의 모두를 위한 RL 강좌 lecture 4를 듣고 정리하였다.
이전의 Dummy Q-Learning 알고리즘만으로는 최적의 경로를 찾지 못할 수도 있다.
만약, 처음에 아래의 파란색 경로로 Goal에 도착했다고 하면 이전의 알고리즘은 몇 번을 반복해도 파란색 경로로 길을 찾을 것이다. 하지만 파란색 경로보다 빨간색 경로가 더 최적의 경로이다.
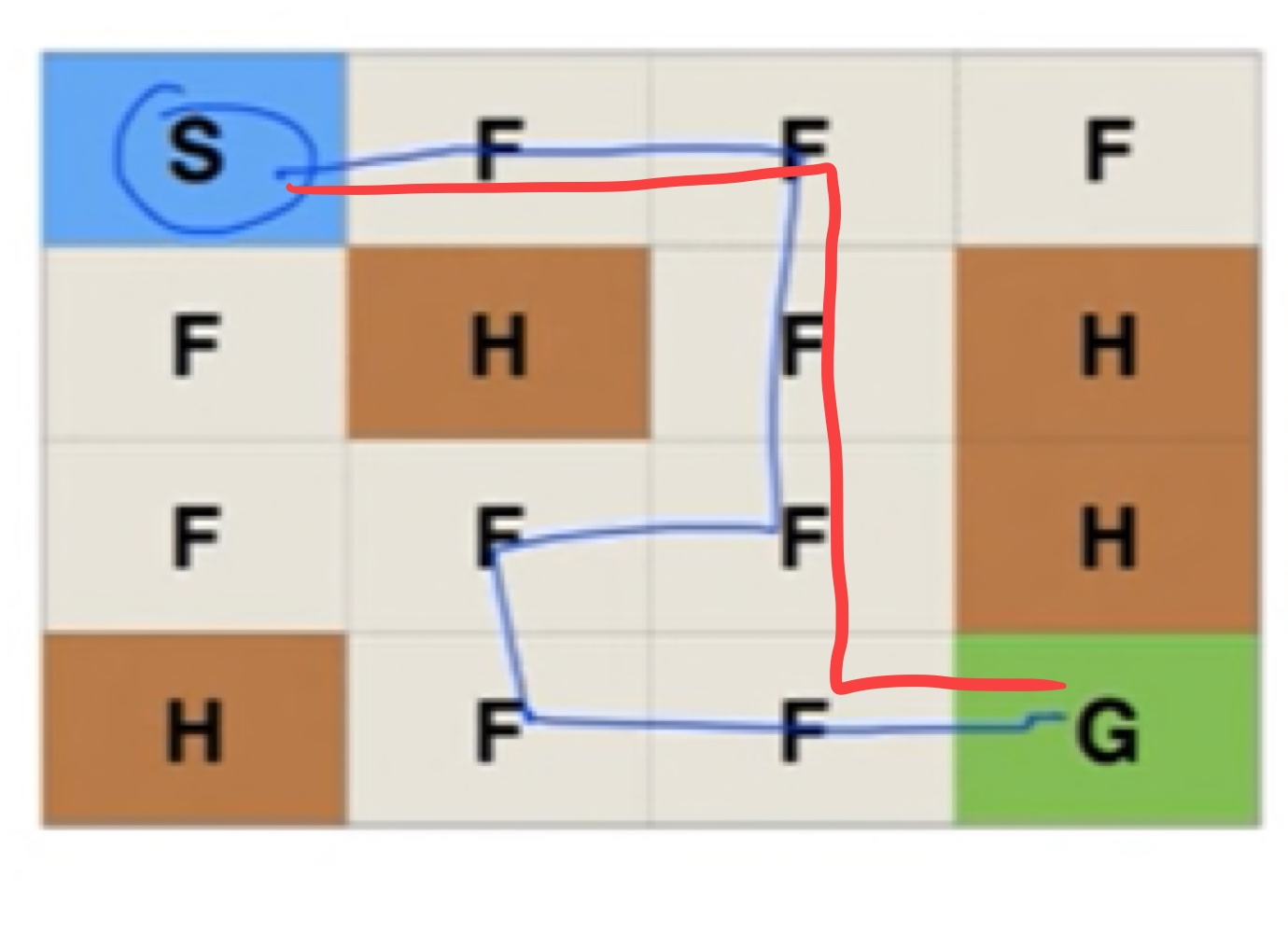
이번 강의는 항상 최단 거리의 경로를 찾으려면 어떻게 해야할까?에 대한 내용이었다.
Exploit vs Exploration
현재 있는 값을 이용 vs 모험, 안 가본 길로 가본다.
이전 알고리즘에서 action a를 선택하는 방법을 바꾼다.
이를 구현하는 방법은 Egreedy 방법과 random noise를 추가하는 방법이 있다.
1-1) Egreedy
e = 0.1
if rand < e:
a = random
else:
a = argmax(Q(s,a))
- 랜덤한 값이 e보다 작으면, 랜덤하게 가본다.
- e보다 크면 알고 있는 길로 간다.
1-2) decaying Egreedy
for i in range(1000)
e = 0.1 / (i+1)
if rand < e:
a = random
else:
a = argmax(Q(s,a))
학습을 거듭해 갈수록 랜덤하게 갈 필요가 없어진다.
뒤로갈수록 랜덤하게 갈 확률이 적어지도록 e의 값을 줄여준다.
2) add random noise
a = argmax(Q(s, a) + random_values)
a = argmax([0.5, 0.6, 0.3, 0.2] + [0.1, 0.2, 0.7, 0.3, 0.1])
우리가 현재 알고 있는 값에 랜덤한 값을 더해서 가장 큰 값인 action을 선택
이때도 decay를 할 수 있는데,
랜덤한 값을 줄여주면 원래꺼가 채택될 것이다.
for i in range(1000)
a = argmax(Q(s, a) + random_values/(i+1)
Discounted future reward

여기서 $\gamma$는 1보다 작은 수이다.
다음 state에서의 리워드 값에 1보다 작을 수를 곱해주게 되면, 현재 s에서 멀리 떨어져있는 곳일수록 reward가 작아지게 된다.
다음 예시를 보면 이해가 쉽다. 다음 그림과 같이 Agent가 10번 자리에 위치해있을 때, Agent가 방향(action, a)을 정해야한다. discounted future reward를 통해 계산된 Q값을 바탕으로 Agent는 Down을 선택할 것이다.
0.9가 곱해지게 되어서 많은 길을 거쳐서 가야하는 방향의 Q값이 작아지게 된다.

위의 내용을 정리하여 Q-Learning 알고리즘을 정리하면 다음과 같다.
a를 선택하는 과정에서 E&E를 사용하고 Q 값을 업데이트 하는 과정에서 discount future reward를 사용한다.

'Deep Learning > RL' 카테고리의 다른 글
| [모두RL-⑥] DQN (0) | 2022.03.07 |
|---|---|
| [모두RL-⑤] Q-Network (0) | 2022.03.07 |
| [모두RL-④] Stochastic (non-deterministic) (0) | 2022.03.07 |
| [모두RL-②] Dummy Q-Learning (table) (0) | 2022.03.06 |
| [모두RL-①] 강화학습 소개 (0) | 2022.03.04 |
댓글