[패스트 캠퍼스] 김기현의 딥러닝을 활용한 자연어생성 올인원 패키지 Online.
Ch 04. Sequence-to-Sequence
06. Attention
07. Masking
강의를 듣고 작성하였다.
본 게시물의 모든 출처는 [패스트 캠퍼스] 김기현의 딥러닝을 활용한 자연어생성 올인원 패키지 Online.에 있다.
(혹시 본 포스팅이 저작권 등의 문제가 있다면 알려주세요. 바로 내리도록 하겠습니다.
개인 공부 후 언제든지 다시 찾아볼 용도로 작성하고 있습니다.)
+ 추가
설명 중 참고한 자료: https://wikidocs.net/24996 → 정말 쉽게 잘 설명되어 있는 자료!
코드 출처: 김기현님 github
기존에 배웠던 seq2seq 모델은 인코더에서 입력 시퀀스를 context vector라는 하나의 고정된 크기의 벡터 표현으로 압축하고, 디코더는 이 context vector를 통해서 출력 시퀀스를 만들어냈다.
▷▷ Attention이 없는 seq2seq 모델은 문제가 있다.
1. 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 한계가 있고 무한하지 않다.
인코더에서 다루는 time step이 엄청 클 때 hidden state가 모든 정보를 담을 수 있을까?
인코더의 마지막 hidden state = 디코더의 첫번째 hidden state 일텐데, 모든 정보를 전달할 수 없으니 한계가 생길 것
또는, 인코더 자체의 성능이 떨어질 수 있다.
(디코더가 아무리 뛰어나도 올바른 정보를 생성하는데에 어려움이 있을 수 있다.
2. RNN의 고질적인 문제인 기울기 소실(Vanishing gradient) 문제가 존재한다.
어텐션(Attention)
입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보정해주기 위해 등장하였다.
아이디어
디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다.
단, 전체 문장을 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관 있는 입력 단어의 부분을 좀 더 집중(attention)해서 본다.
- 미분가능한 Key-Value Function 이다.
Key-Value 자료형
ex) python 딕셔너리(Dict) 자료형
d = {"key1":"value1", "key2":"value2"}
d[Q] → value1 이기 위해서는 Q = key1 완전히 일치해야한다.
즉, 기존의 Key-Value 자료형에서는 Query와 Key가 완벽히 일치해야 Value를 가져올 수 있었다.
- 기존의 Key-Value Function과 달리, Query와 Key의 유사도에 따라 Value를 반환한다.
- Query에 대해서 모든 Key와의 유사도를 각각 구한다. 그리고 구해낸 유사도를 키와 맵핑되어있는 각각의 Value에 반영해준다. 그리고 유사도가 반영된 Value 모두 더해서 리턴한다. 이를 어텐션 값(Attention Value)라고 한다.
- Decoder RNN(LSTM)의 hidden state의 한계로 인해 부족한 정보를 직접 encoder에 조회하여 예측에 필요한 정보를 얻어오는 과정
- 정보를 잘 얻어오기 위해 Query를 잘 만들어내는 과정을 학습한다. (즉, Query를 만드는 방법을 학습한다.)
Seq2Seq + Attention
Query: 현재 time step의 decoder output
Keys: 각 time step 별 encoder output
Values: 각 time step 별 encoder output
어텐션 이해하기 위한 전체적인 구조
디코더에서 세번째 LSTM 셀에서 출력 단어를 예측할 때, 어텐션 메커니즘을 사용하는 것을 보여준다.
디코더의 첫번째, 두번째 LSTM 셀은 이미 어텐션 메커니즘을 통해 je와 suis를 예측했다고 가정한다.
아래의 그림과 밑에 설명을 통해 Seq2Seq 모델에서 Attention이 어떻게 작동하는지 공부했다.

1) 디코더에서 출력 단어를 예측하기 위해 인코더의 모든 입력 단어들의 정보를 다시 한 번 참고한다.
- Query를 만든다.
- 어텐션 스코어(Attention score)를 구한다. (Q·K)
2) 인코더 input 단어 각각이 출력 단어를 예측할 때 얼마나 도움이 되는지 정도를 수치화한 값을 구한다. w
- 소프트맥스 함수를 통해 어텐션 분포(Attention Distribution)를 구한다.
3) 하나의 정보로 담아서 디코더로 전송한다. (Context vector) c
- 각 인코더의 어텐션 가중치와 hidden state를 가중합 하여 어텐션 값(Attention value)을 구한다.
4) 어텐션 값과 디코더의 t시점의 hidden state를 연결한다.(Concatenate)
5) 디코더의 hidden state를 재정의 하고 generator에 넘겨준다.

↓코드↓
Attention 코드
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.linear = nn.Linear(hidden_size, hidden_size, bias=False)
self.softmax = nn.Softmax(dim=-1)
def forward(self, h_src, h_t_tgt, mask=None):
# |h_src| = (batch_size, length, hidden_size)
# |h_t_tgt| = (batch_size, 1, hidden_size)
# |mask| = (batch_size, length)
query = self.linear(h_t_tgt)
# |query| = (batch_size, 1, hidden_size)
weight = torch.bmm(query, h_src.transpose(1, 2))
# |weight| = (batch_size, 1, length)
if mask is not None:
# Set each weight as -inf, if the mask value equals to 1.
# Since the softmax operation makes -inf to 0,
# masked weights would be set to 0 after softmax operation.
# Thus, if the sample is shorter than other samples in mini-batch,
# the weight for empty time-step would be set to 0.
weight.masked_fill_(mask.unsqueeze(1), -float('inf'))
weight = self.softmax(weight)
context_vector = torch.bmm(weight, h_src)
# |context_vector| = (batch_size, 1, hidden_size)
return context_vector
Masking on Attention
- 어텐션을 실제로 구현할 때 생기는 문제점을 해결하기 위해 제안된 방법
- 우리는 미니배치로 묶어서 학습을 한다.
- 문장 길이가 다르기 때문에 미니배치를 구성하고 있는 문장 중 가장 긴 문장에 맞춰서 다른 짧은 문장들에는 <PAD>로 길이를 맞춰준다.
- 문장이 어떻게 구성되느냐에 따라서 <PAD>가 동적으로 생성된다.
- <PAD>의 hidden state에는 attention weight가 할당되면 안된다 → 할 때마다 바뀌기 때문이다.
- 따라서 Key와 Query의 dot product 이후에 (softmax 이전에), masking을 통해 <PAD> 위치의 값을 음의 무한대($-\infty$)로 변경한다.
- softmax 결과, <PAD>에는 0이 할당된다.
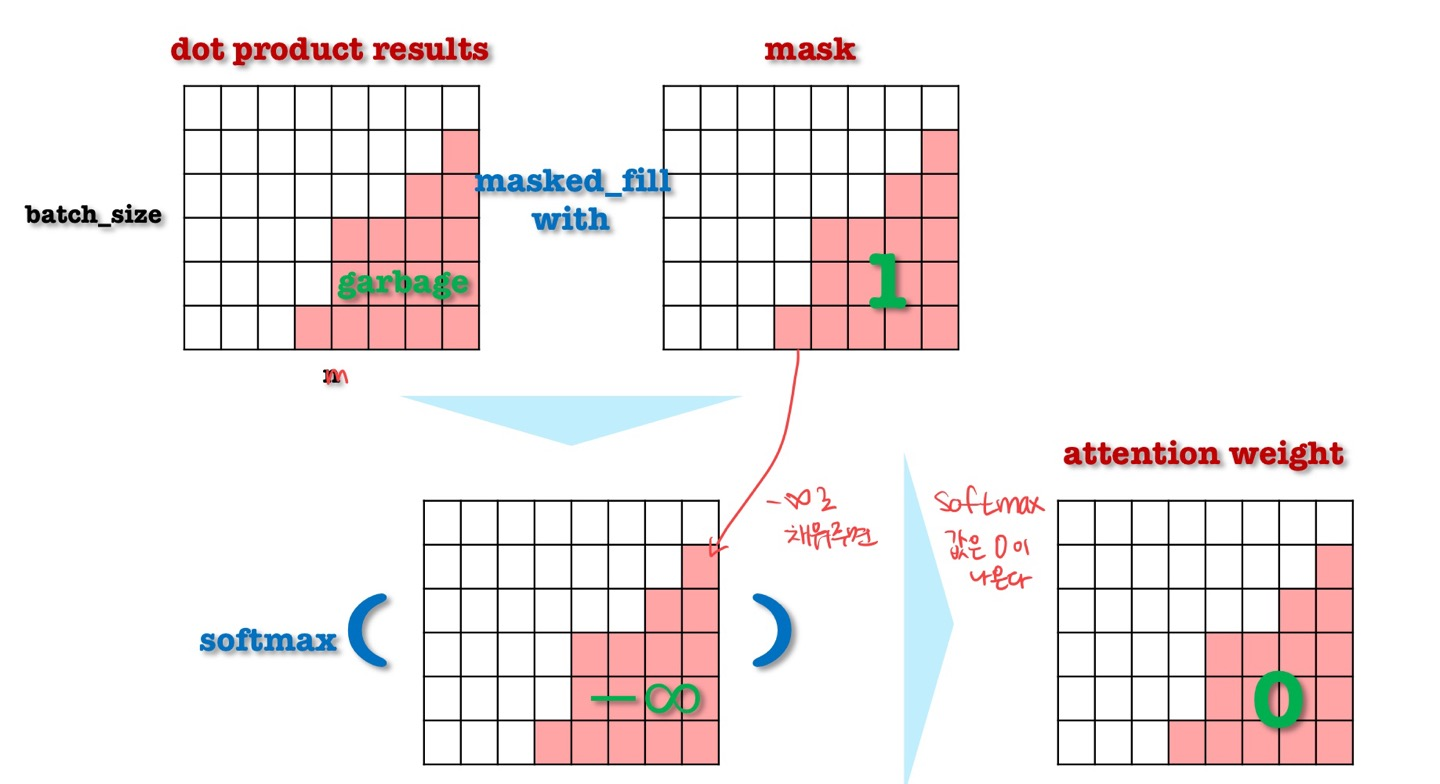
출처: 패스트캠퍼스 김기현의 자연어 처리 생성
- softmax 결과, <PAD>에는 0이 할당된다.
'Deep Learning > NLP' 카테고리의 다른 글
| [패캠] (Seq2Seq) Input Feeding & Teacher Forcing (0) | 2022.02.15 |
|---|---|
| [패캠] (Seq2Seq) seq2seq 모델 (0) | 2022.02.06 |
| [패캠] (LM) Neural LM (0) | 2022.02.05 |
| [패캠] (LM) 기존의 언어 모델 (0) | 2022.02.05 |
| [패캠] (LM) 언어모델 (0) | 2022.02.05 |
댓글