[딥러닝 모델 경량화] 딥러닝 경량화 기술 동향
지난 학기에 DCASE라는 대회에 참여하였었는데, 그 주제가 모델 사이즈는 500MB 이하인 상태로 성능을 좋게하는 것이었습니다. 대회는 끝났지만, 좀더 결과물을 발전시키고자 딥러닝 경량화 기술에 대해 공부하기로 하였습니다.
먼저 저는 다음의 참고자료를 활용하여 공부하고 정리하였습니다.
참고:
[1] 경량 딥러닝 기술 동향, ETRI 2019, 이용주, 문용혁, 박준용, 민옥기
[2] 김동이님 발표, '더 효율적이고 경량화된 Convolution Neural Network 설계 기법'
[3] 인공지능 경량화 기술 동향, Samsung sds
Deep Neural Network 경량화
비슷한 수준의 성능을 유지한채 더 적은 파라미터 수와 연산량을 가지는 모델을 만드는 것을 모델 경량화라고 합니다.
경량 딥러닝 기술은 크게 두가지로 나눠집니다.
1. 경량 알고리즘 연구
알고리즘 자체를 적은 연산과 효율적인 구조로 설계하여, 기존 모델 대비 효율을 극대화시킵니다.
2. 알고리즘 경량화
만들어진 모델의 파라미터들을 줄이는 모델 압축과 같은 기법이 적용됩니다.
이제 이 두가지 연구에 어떤 것이 있는지 대해서 알아보도록 하겠습니다.
1. 경량 딥러닝 알고리즘
가장 일반화된 CNN을 통해 다양한 연구가 진행되고 있습니다.
1) 모델 구조 변경
단일 층별 연산에서 그치지 않고 잔여 블록, 병목구조, 밀집 블록 등과 같은 형태를 반복적으로 쌓아 신경망으로 구성하는 다양한 신규 계층 구조를 이용하여 파라미터 축소 및 모델 성능을 개선하는 연구가 진행되고 있습니다.
- ResNet
- DenseNet
기존 신경망 모델 구조의 여러 장점을 모아 고안한 모델입니다.
기존 피쳐맵을 더해주는 게 아닌 쌓아가는 과정을 거치며 모델의 성능을 높이고자 하였습니다.
- SqueezeNet
기본적으로 사용하는 합성곱 필터인 3X3 필터를 1X1 필터로 대체하여 9배 적은 파라미터를 가집니다.
1X1 합성곱을 이용하여 채널 수를 줄였다가 다시 늘리는 파이어 모듈(Fire Module) 기법을 제안하였습니다.
늦은 다운 샘플링 전략을 통해 한번에 필터가 볼 수 있는 영역을 좁히면서 해당 이미지의 정보를 압축시키는 효과가 있습니다.
2) 합성곱 필터 변경
이 기술에 대한 연구가 주로 이루어지고 있다고 합니다.
합성곱 신경망의 가장 큰 계산량을 요구하는 합성곱 필터의 연산을 효율적으로 줄이는 연구입니다.
모델 구조를 변경하는 다양한 경량 딥러닝 기법은 점차 채널을 분리하여 학습시키면서 연산량과 변수의 개수를 줄일 수 있는 연구로 확장되었습니다.
일반적인 합성곱은 채널 방향으로 모두 연산을 수행하여 하나의 특징을 추출하는 데 반해, 채널별(Depthwise)로 합성곱을 수행하고, 다시 점별(Pointwise)로 연산을 나누어 전체 파라미터를 줄이는 것과 같이 다양한 합성곱 필터를 설계하기 시작하였습니다.
- MobileNet
기존의 합성곱 필터를 채널 단위로 먼저 합성곱(Depthwise Convolution)을 하고, 그 결과를 하나의 픽셀(Point)에 대하여 진행하는 합성곱(Pointwise Convolution)으로 나눔으로써 한 예로, 필터의 가로, 세로 길이를 3이라고 할때, 약 8~9배의 이득이 있게 한 네트워크입니다.
- ShuffleNet
점별 합성곱(Pointwise convolution)시 특정 영역의 채널에 대해서만 연산을 취하는 형태로 설계하면 연산량을 매우 줄일 수 있을 것이란 아이디어에서 출발하였습니다. 입력에서만의 정보 흐름만을 취하는 대신, 입력의 각 그룹이 잘 섞일 수 있도록 개선한 것이 핵심입니다.
3) 자동 모델 탐색
기존 신경망의 모델 구조를 인간에게 의존적으로 수행하지 않고 모델 구조를 자동 탐색하는 기술들에 대해 연구가 이루어지고 있다고 합니다. 특정 요소(지연시간, 에너지 소모 등)가 주어진 경우, 강화 학습을 통해 최적 모델을 자동 탐색하는 연구입니다.
- NetAdapt(넷어덥트)
- MnasNet(엠나스넷)
2. 알고리즘 경량화
기존 알고리즘의 불필요한 파라미터를 제거하거나, 파라미터의 공통된 값을 가지고 공유하거나, 파라미터의 표현력을 잃지 않으면서 기존 모델의 크기를 줄이는 연구 분야입니다.
1) 모델 압축 기술
- Pruning
기존 신경망이 가지고 있는 가중치 중 작은 가중치값을 모두 0으로 하여 네트워크의 모델 크기를 줄이는 기술입니다.
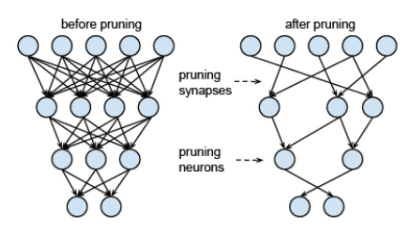
- Quantization / Binarization
Quantization은 특정 비트 수만큼으로 줄여서 계산하는 방식입니다. 파라미터의 Precision을 적절히 줄여서 연산 효율성을 높이는 방법입니다. 16bit, 8bit 이런식으로 줄여서 사용합니다.
- Weight Sharing
낮은 정밀도에 대한 높은 내성을 가진 신경망의 특징을 활용해 가중치를 근사하는 방법입니다.
2) 지식 증류 기술 (Knowledge Distillation)
앙상블 기법을 통해 학습된 다수의 큰 네트워크로부터 작은 하나의 네트워크에 지식을 전달할 수 있는 방법론 중의 하나입니다.
Teacher 모델을 Student 모델 학습에 활용합니다.
3) 하드웨어 가속화 기술
벡터/행렬 연산을 병렬 처리하기 위한 전용 하드웨어 (TPU), VPU, GPU Custer 기반 가속기 등의 연구개발이 주요 IT 기업에 의해 주도되고 있다고 합니다.
4) 모델 압축을 적용한 경량 모델 자동 탐색 기술
Pruning, Quantization 등의 탐색 공간을 통한 자동화 연구가 진행되고 있습니다.
'Deep Learning' 카테고리의 다른 글
| [딥러닝 모델 경량화] Inception (0) | 2020.08.02 |
|---|---|
| [딥러닝 모델 경량화] 다양한 종류의 Convolution (3) | 2020.08.01 |
| [Hands-on-ml-2] 모델 평가 (0) | 2020.07.30 |
| [hands-on-ml-2] 범주형 데이터 다루기 (0) | 2020.07.25 |
| [모두를 위한 머신러닝/딥러닝] ML (0) | 2020.07.09 |
댓글